A Comprehensive Guide to Data Pipelines: Understanding Components, Processes and Steps for Effective Data Management
Have you ever wondered how the raw data from your streaming applications or customer logs is turned into insights? It’s a complex process of data processing and transformation that provides the informed decision required for your business. But where does it all happen? How does data from diverse sources get ingested into one destination, cleaned, validated and then transformed into valuable insights? The answer is a data pipeline, a system that simplifies these complex processes and provides a streamlined path for your data.
What is a Data Pipeline?
A data pipeline serves as the transport system that pipes the raw data from the source and transforms it into a structure or format that assists in easy analysis and storage of the data. Remember, every format or structure of the data is not feasible to analyse. For example, suppose you choose a NoSQL database as your data repository location. In that case, formatting data models as key store values, column families, or graphs helps align with the NoSQL database. This helps with seamless and efficient data processing and analysis. In other words, the data pipeline process involves a series of interconnected operations where your data moves seamlessly from one part of the component to the next to ensure your data preparation tasks happen effectively. This helps your business get accurate, consistent, and formatted data to proceed.
The introduction of big data plays a major role in the processing and types of data pipelines. To accommodate such a large volume, velocity, and variety of data, an advanced and sophisticated data pipeline process that helps organisations analyse data as it arrives is required. A few popular and advanced data pipelines available on the market are Azure Data Factory, AWS Data Pipeline, Google Cloud Dataflow, and Apache Airflow.
When Should Your Organisation Consider Adopting a Data Pipeline Solution?
Before proceeding with the data pipeline, it is crucial to understand when your organisation should opt for one. This is important because it helps in designing and learning what kind of data pipeline will suit your business. If any of the following requirements match your organisation, then your organisation should consider implementing a data pipeline without any delay.
- Big Data: Does your organisation deal with high volumes, velocity, and variety of data? Then, opting for a data pipeline will be a wise choice, as it helps automate and streamline your data from sourcing to delivery.
- Real-time Insights: Are you planning to process and analyse the data in real-time to strategise operational efficiencies? Choosing a data pipeline with real-time processing helps your organisation analyse and visualise insights crucial for informed decision-making.
- Data Quality and Accuracy: Is your organisation facing challenges with ensuring data quality? A data pipeline will help clean, enrich and filter data, resulting in a complete and accurate data output.
- Scalability Requirements: Are you confused about the growing data volume? Implementing a data pipeline helps handle the requirement by scaling data processing needs and storage capacity.
Types of Data Pipeline
Every organisation operates with completely different business objectives and goals, which means it has different data and processing requirements. This demands a different data pipeline. Let’s discuss the three common data pipelines in the industry.
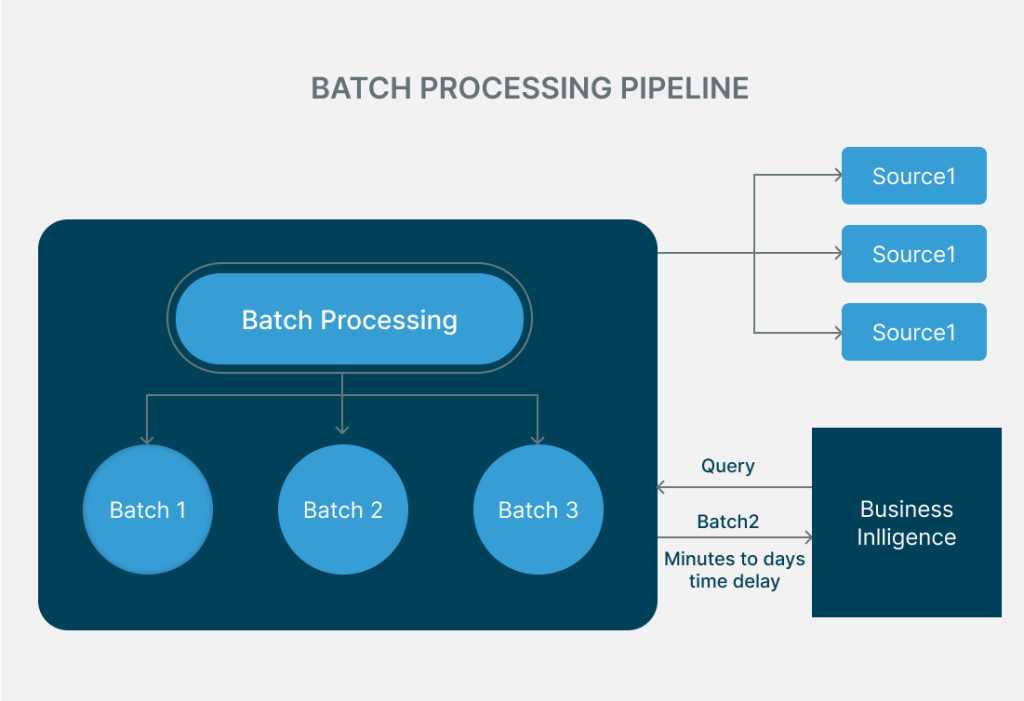
1. Batch Processing
As the name suggests, batch data pipeline processing is a process performed at regular intervals where data is collected, transformed, and then stored in batches. This process is applicable to business operations that do not require real-time data processing. The batch data pipeline process is advantageous in situations where organisations need to process large volumes of datasets or accomplish complex operations effectively and efficiently with minimal usage of power, memory and I/O operations.
For example, a retail company’s sales data from all branches collected throughout the day is processed in batches before the next day’s sales begin. This way, the company ensures that no data is left behind and also makes sure the company’s data dashboard is updated with new sales insights for the next day’s business.
2. Real-time Processing
Unlike batch processing, this type of data pipeline process is crucial for businesses demanding real-time insights. In this process, data continuously flows through the pipeline, ensuring the data is processed, transformed, and analysed as and when it arrives, resulting in minimal latency. The data pipeline utilises event-driven architecture to initiate or notify the processing to happen as the data moves in. This type of data pipeline process helps organisations or businesses in healthcare, fintech, and other industries rely on immediate insights like fraud detection, patient vital monitoring, and IoT applications. One of the major concerns in real-time processing is its ability to scale efficiently to handle large volumes of data then and there.
Imagine a banking institution constantly struggling to monitor and detect fraud and data breaches. Leveraging a real-time data pipeline process helps track customer applications, transaction details, and other data in real-time. This helps the bank spot the threat or malicious actor before any major mishaps can happen.
3. Hybrid Processing
This type of data pipeline process provides organisations with the flexibility to perform batch or real-time processing based on the data type and processing requirements. With a hybrid data pipeline process, organisations can have a dual-processing mode where large volumes or periodic data are processed in batches. In contrast, real-time processing is used for data requiring immediate attention and analysis. This helps in handling varying data loads and storing data from both processes in respective repositories, like real-time processed data in a NoSQL database for immediate access, whereas batch-processed data is stored in data lakes or data warehouses. Leveraging a hybrid processing data pipeline allows organisations to achieve timely insights and efficient data management, supporting a wide range of business needs and use cases.
For example, in healthcare, patient vitals and scan reports are processed in real-time to alert or notify physicians of current health concerns, whereas patient information such as appointment date, time, and name is processed in batches, ensuring the details get updated in the health record overnight.
Maximise data handling capabilities. Explore our comprehensive Data Management Solution

The Components of a Data Pipeline
As stated, a data pipeline is a series of interconnected elements that house the following components to perform operations such as masking, filtering, and enriching data. Let’s analyse the components that constitute a modern data pipeline.
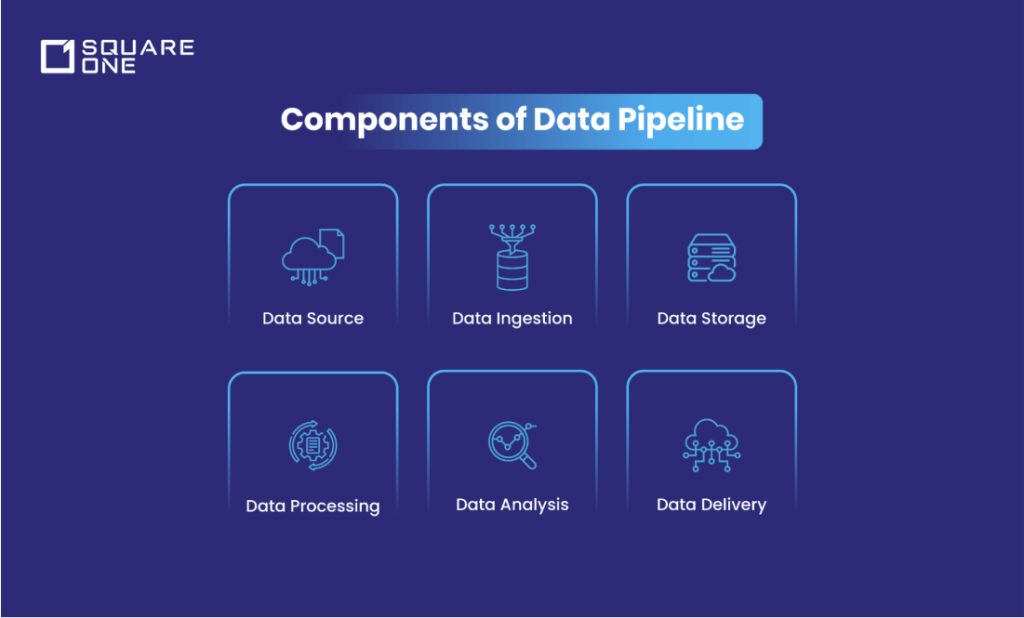
Data Source
As a fundamental element of a data pipeline, the data source plays a major role by providing reliable and accurate data from diverse sources such as APIs, customer logs, social media analytics, sales, transaction details and many others. These data are of varying formats and types, like structured data, unstructured data, semi-structured data and streaming data.
For example, the data derived from your social media platform is unstructured, for it includes multimedia content (images, videos), free-form texts and diverse metadata, lacking a predefined model schema. However, every data source is essential for deriving insights and making informed decisions.
Data Ingestion
The next step involves collecting and transferring data from various sources to the pipeline. It is one of the most crucial processes, for it enables the execution of subsequent stages, such as data processing and analysis. An effective data ingestion process ensures the sourced data is cleaned, verified and transformed into formats aligned with the respective repositories or storage locations.
Organisations can automate the data ingestion process, resulting in reduced manual effort in data collection and optimisation. Along with data collection, the ingestion process facilitates the capture of metadata information like the timestamp of data collection, who initiated the capture, and other relevant contexts needed for understanding and processing the data
Data Storage
Once the data has been ingested, it is time to organise and store the cleaned and transformed data in respective storage or repository locations where it can be readily accessed and utilised for various business functions like processing and analysis. As a centralised location, indexing data based on key attributes helps organisations retrieve them quickly in real-time processing.
Also, while designing the data storage, make sure it can scale seamlessly to handle large volumes of data and is compatible with data processing engines like Spark, Hadoop and other platforms. The storage or repository varies based on the data format and pipeline requirements. For example, the NoSQL database is best for unstructured and semi-structured data, while the data warehouse handles only structured data from transactional systems.
Data Processing
This component of the data pipeline is responsible for transforming raw data into readable and accessible formats that help with easy interpretation, data analysis, and accurate decision-making. The following are the tasks that happen in this component to help organisations meet requirements and goals.
- Data Cleaning: Helps detect inaccurate or corrupted data by addressing issues like missing data values, outliers and non-relevant data.
- Data Aggregation: Provides a comprehensive view of the data by summing up numerical values, averaging metrics or generating statistical metrics.
- Data Normalisation: Ensures the consistency of data by eliminating discrepancies or differing units and adjusting the data values to a standardised range such as 0 to 1 or 1 to -1.
- Data Filtering: This involves applying pre-defined criteria to select only relevant and necessary data from large datasets, reducing the volume of the data and the accuracy of the analysis.
- Data Enrichment: Enhances the dataset with additional attributes by integrating external data sources like APIs or third-party databases, thereby increasing the depth and quality of the data.
Data Analysis
Once the data has been prepared, it is time to analyse the sourced and processed data to extract insights that help drive informed decisions to support strategic and operational business processes. With data analysis, organisations can study consumer behaviour, discover hidden patterns and forecast trends, challenges and opportunities, leading to being ahead of the competition curve. The following are the types of data analysis supporting various trends and forecasts.
- Descriptive analytics uses statistical algorithms (mean and variance) to correlate historical data and study what has happened.
- Diagnostic analytics examines data to determine the cause of previous outcomes through techniques such as correlation or drill-down analysis.
- Predictive analytics implements statistical models and machine learning algorithms on historical data to predict future outcomes.
- Prescriptive analytics utilises optimisation or stimulation to recommend organisational suggestions or actions to be performed to achieve desired outcomes.
Thus, data analysis plays a major role in assisting organisations in identifying inefficiencies, forecasting potential areas of improvement, and examining past opportunities. This allows organisations to mitigate potential risks and challenges.
Data Delivery
As a final component in the data pipeline, this ensures that the sourced, cleaned, enriched, transformed, and processed data is finally transferred from the pipeline to the destination, from where organisations can access the data for insights and information. This process involves leveraging various data delivery methods like APIs, data connectors, integration and loading mechanisms to meet various delivery options like, bulk transferring, different sources and destinations, or smooth data loading. Also, by automating the data delivery process, organisations can make sure that timely access to high-quality data is available to extract insights for informed decision-making and operational efficiency.
From Data Sources to Insights: A Data Pipeline Process in E-Commerce
As we discussed the components, let’s get into the data pipeline process by citing a hypothetical scenario
Imagine an e-commerce company wanting to improve its recommendation system by analysing customer purchase history, behaviour, and patterns. Before starting the process, the company would identify the data sources available to gather data.
- Structured data from transaction records
- Unstructured data contains customer reviews from social media platforms
- Semi-structured data encompasses customer details from JSON file
- Real-time data from the company’s websit
- The next step is to ingest the data, which means collecting various data types. The streaming data, such as the click rate and page view from the website, are captured in real-time, whereas the data from MySQL and JSON files is entered into the system at the end of the day. Additionally, the data from social media helps in collecting sentiment analysis and feedback.
- The gathered data now needs to be stored, and this depends on the data format or structure. The transaction and customer information data are structured and stored in a relational MySQL database. In contrast, the social media data is stored in Data Lakehouse, which supports the storage of both structured and unstructured data.
- The company now moves to process the stored data by cleaning, enriching or filtering the data to focus on the most relevant and important ones. The transaction records are cleaned to remove duplicates or handle missing values, and then enriched with additional attributes like demographic fields sourced from third-party sites. The streaming data is aggregated to study user behaviours, like session duration, whereas the review data is normalised for consistent sentiment analysis. This helps organisations erase data that is repetitive, non-relevant and non-usable.
- Once the company is ready with the prepared data, the data scientists and analysts start to perform descriptive analytics on transaction data, predictive analytics to forecast future purchasing behaviour, and diagnostic analytics on streaming data to identify any challenges in the customer journey.
- Finally, it is time to deliver the processed and analysed data to its intended destination. APIs support this by delivering the enriched data to the recommendation engine, improving the system’s accuracy. The data connectors ensure that the aggregated data is fed into the intelligence dashboards, helping stakeholders view and visualise insights and critical data points in real time.
Thus, the data pipeline process plays an important role in enhancing and improving an e-commerce company’s recommendation engine by sourcing, ingesting, enriching, and transforming the data into valuable insights and informed decisions.
Simplify your big data struggles. Discover our robust Big Data solutions
Establishing a Dynamic Data Pipeline: Key Steps
A few steps must be followed before considering the design and building of a data pipeline. This way, organisations can ensure that the designed data pipeline is robust, secure, scalable and efficient.
Step 1: Define Objectives and Data Sources
- Start the data pipeline design by establishing your organisation’s aim for building this data pipeline, such as achieving real-time insight, improving the recommendation engine, and generating reports.
- This helps your organisation focus on the components necessary for the defined objective. It is also essential to list the sources involved in this process, helping to analyse the scalability, performance, and compliance needs effectively.
Step 2: Design the Data Pipeline Architecture
- Once the objectives and requirements are defined, the data pipeline architecture must align with the established goals. Select the one that best suits your business needs, whether batch processing, real-time processing, or a hybrid model.
- Also, make sure to outline the data flow process from the source to the destination, along with the necessary methods such as cleaning, enriching, and normalisation.
Step 3: Set up Data Ingestion and Storage
- Analysing and finalising the data ingestion and storage processes is crucial, for this helps determine the performance of the data pipeline.
- In addition, select the data storage solution based on the type of data your organisation deals with. Implementing indexing, partitioning, and metadata in storage solutions helps facilitate data retrieval.
Step 4: Determine Data Processing and Transformation
- In this step, make sure to list the necessary formatting options your data needs to follow, such as cleaning, filling, or removing duplicates. This helps the data pipeline focus only on the data delivery process.
- Also, establishing the processing type, such as Extract, Transform and Load (ETL) or Extract, Load and Transform (ELT), helps determine the processing strategies and approvals in advance, resulting in a seamless and efficient process.
Step 5: Implement Secure Data Delivery
- This step requires meticulous attention, for this is where your data gets transferred to its destination. Determining secure protocols such as encryption and access controls ensures the data stays protected and safe in transit.
Step 6: Track Data Pipeline Performance
- Utilise tools and techniques to monitor the effectiveness, efficiency and error in the data pipeline. This helps track the areas of improvement and failure zones.
- Regular checks on performance, updates and efficiency also help keep the data pipeline efficient, accurate and seamless.
Step 7: Perform Testing and Validation
- As the final step in the series, completing the process by testing the data pipeline helps identify the data flow, component efficiency and insight accuracy.
- This also helps verify the completeness of the data, ensuring only consistent data has been collected and utilised in deriving the insight.
Thus, following the above-mentioned steps helps organisations not only design and build a data pipeline but also assist in maintaining an effective data management system that keeps data secure and protected from unauthorised access and data breaches.
Comparison of Data Pipelines vs. ETL
The ETL process frequently misunderstands the data pipeline process. Understanding the differences is necessary to utilise the best one that suits your business. Here’s a tabular column that clearly clarifies how both are unique and efficient in their own ways.
Aspects | Data Pipeline | Extract, Transform and Load |
|---|---|---|
Definition | A modern approach that involves automating the data workflow from sourcing to delivery. | It is a traditional practice in the data integration process that involves extracting data from a source, transforming it according to business requirements, and loading it to a targeted destination. |
Processing Types | Supports both batch and real-time processing | The ETL focuses mainly on batch processing but extends support for near real-time capabilities. |
Data
Movement | In a data pipeline, data moves continuously or at specified intervals, supporting both structured and unstructured data. | In the ETL process, only structured data is accommodated, and this moves in bulk at specified durations, primarily at night. |
Usage | Suitable for modern data architecture where data sources are diverse and processing needs are challenging. | This process works well in data warehousing, where data needs to be cleaned, transformed and integrated before analysis. |
Flexibility | It offers flexibility in handling data of diverse types and formats, which helps it adapt to various business needs and data sources. | The ETL process is less adaptable than a data pipeline. It supports only structured data and pre-defined transformation rules, making it rigid and non-scalable to evolving business needs. |
Key Applications | Example: AI is used in robotics, autonomous vehicles, virtual assistants (e.g., Siri, Alexa), smart home devices, and healthcare diagnostics. | Example: ML is used in banks to detect real-time fraudulent activities. It is also helpful in product recommendation and facial recognition. |
Implementation Needs | Implementing AI systems requires precise planning with high-quality data. The selected AI model should be able to automate repetitive learning and solve complex tasks. | Implementing ML models requires the right data capture, which needs to be prepared. Then, based on business requirements, the right model needs to be chosen and trained to make data-driven decisions. |
Resource Requirements | To implement and maintain, it required an effortless AI system, robust IT infrastructure, high computation power, large-scale data analysis, and well-trained AI experts. | An effective ML model requires fewer resources than AI. However, competent datasets are required to train and deploy the ML model. |
System Integration | Scalability, interoperability, and frequent updates are involved to ensure seamless integration with various technologies and systems | Real-time processing, datasets from diverse formats and APIs are required in deploying the ML models into the existing systems of a business. |
Scope of Adaptability | Various industries and domains have integrated AI systems that foster everything from simple automation to complex problem-solving. | Adaptable to environments where continuous learning and training from data are processed. |
Before concluding, let’s discuss one final concept of a data pipeline—on-premise or in the cloud. To be specific, a data pipeline can be implemented both on-premise and in the cloud, but this depends on your organisation’s infrastructural flexibility and scalability offerings.
On-Premise Data Pipeline
- As the name suggests, the data pipeline is implemented within your organisation’s own physical data centre.
- This type of solution is appreciated when data security is the primary concern, as having an on-premises helps organisations maintain and customise the security factor, reducing third-party interference and unauthorised access.
- An on-premise data pipeline requires robust hardware and software capabilities that support business processes of all kinds. A well-studied IT team can help you navigate the challenges seamlessly and efficiently.
Cloud Data Pipeline
- Suitable for organisations struggling to process and analyse large volumes of data, reducing additional purchases
- Leveraging a cloud-based data pipeline helps organisations reduce hardware procurement and software licencing costs.
- This provides in-built features such as security protocols, compliance and integration potential.
- As a pay-as-you-go model, this helps organisations pay only for the resources utilised, eliminating overhead expenses.
Both have pros and cons; choosing the one that aligns with your business needs helps you meet objectives efficiently and effectively.
Drive your business forward with clear and actionable insights. Discover our Data Visualisation Solution.
Transforming Your Data Strategy: SquareOne's Approach
To harness the maximum potential of a data pipeline, it is crucial to get professional assistance that guides you through the entire process of setting up a data pipeline from start to finish. This way, your organisation can leverage the most sophisticated form of data pipeline, which is advanced and aligns with your business objectives, ensuring your organisation reaps the maximum benefits. SquareOne, a leading digital transformation company in the Middle East, helps businesses handle their data efficiently by analysing, transforming and processing data in a way that helps generate valuable insights, crucial for operational efficiencies and organisational growth. As a distinguished partner of leading business providers, SquareOne commits to delivering digital solutions that help transform your business to achieve greater efficiency, innovation and growth. To learn more about SquareOne and its offerings, get in touch with experts or professionals today!
Conclusion
To conclude, data pipelines are an essential modern framework, enabling efficient data extraction, transformation, normalisation and processing from diverse sources to a dedicated destination. Apart from this, a data pipeline plays a major role in ensuring the quality, completeness and accuracy of the data. This helps businesses make sure that the derived insights and information are reliable and accurate. Also, the data pipeline supports both batch and real-time processing, helping businesses process data per their requirements and needs. While a data pipeline is advantageous, building it with the help of professional assistance like SquareOne can help your business maximise its potential and deliver expected outcomes.
In this data age, organisations are bound to generate data in various formats and structures. Gathering all of them under one roof is not an easy task, but with a robust and scalable data pipeline, every data operation, such as ingestion, transformation, enrichment and storage, can be performed seamlessly and efficiently without errors or inconsistencies. Looking to build an efficient and powerful data pipeline? Connect with SquareOne and get your data pipeline designed and built by a team of experts, ensuring seamless data integration, processing, and real-time insights for your business!